https://arxiv.org/abs/2006.11280
Introduction
既存のPU Learningでは、代理タスクなどの補助を含む自己教師あり学習は考えられてなかった。この論文では以下のような「自己ブースト」を含んでいる。
- Unlabeledの中から信頼できるものをイテレーションが進むにつれて選ぶ。
- 信頼できないデータについてはMeta Learningの知見でCalibrationをした。
- Teacher, Student Modelを同時に学習させている。
Related Work
PU Learningはわかっているので飛ばす。
Self-paced Learning
カリキュラム学習の一種類で、訓練サンプルを学習ヒストリーをもとに動的に生成するというもの。これにより、最初は簡単で徐々に難しくなるという目標を実現させたい。
具体的には学習の初期で自信のあるサンプルを学習に使い、学習が進むにつれて自信がないサンプルも学習に使っていく。
Noisy LabelにありがちなSmall Loss Trickとは考えが真逆。こっちは学習が進むにつれて自信のあるサンプルだけ見てる。
Self-supervised Learning
Unlabeledの中から、これっぽいとおもうラベルであるPseudo Labelを付与して学習を進めていくもの。これの一種として、データにのいずなどの変換を増やしていくData Augmentationなどがある。
Tarvainen, A. and Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In NeurIPS, 2017.
これは、Teacher, Studentの2つの同じネットワーク構造をした学習器を用意して、
- Studentは普通に学習をする。
- TeacherはStudent Modelの予測値をもとに、Unlabeledのデータに対してPseudo Labelを生成する。これをStudent Modelの学習にも使っていく。
- Teacherのパラメタ更新は、Studentの重みと今のTeacherの重みの移動平均で計算したものである。
- パラメタ自体移動平均で更新しているとはいえ、最終的な出力もStudent ModelとTeacher Modelであまりずれてほしくない。この時以下のMSEも損失に加える。
Proposed Method
流れとしては、
- まずUから自信のあるデータを選んでPseudo Labelをつけて、教師あり学習する。
- Meta Learningを通して、自信のないデータに対する損失関数を調節する。
- 異なる学習ペースを持つ同時に訓練するネットワークに一貫性の損失を導入。
これは先ほど紹介したMean Teacherから啓発を受けているかな。
アルゴリズムの流れは以下のように、訓練段階によって違うことをやる。
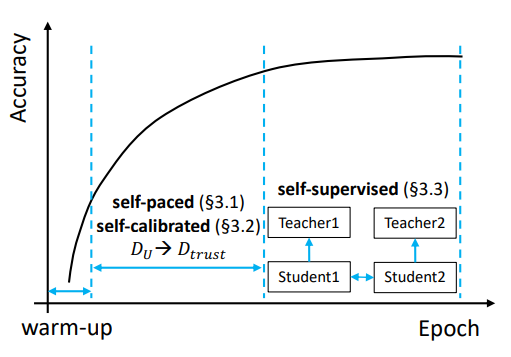
Self-paced PU Learning
Memorization Effectによって、最初は簡単な特徴を持つ例を学習していく。
モデルと入力、ラベルがあるとする。モデルの出力から、確率をcalibrationする感じ。
このように計算した確率を信頼度だとして、一番信頼度が高いPositiveやNegativeと判定されたUnlabeledの中のデータを上から順にいくつか選び(同数選ぶことでbalanced長く種がおのずとできる)、Pseudo Labelを付与してからから除去してに入れる。
そして、でPN Learningを行い(Cross-Entropy Loss)、とでnnPUを行う。
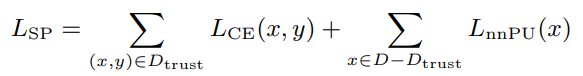
Dynamic Rate Sampling
最初に簡単なデータを、進むにつれて難しいデータを学ばせるために、に加える敷居を動的に決めるようなフレームワークを考えた。
線形に増加して、割合は最初は10%から最大で40%まで増やす。
なお、Self-paced PU Learningをする前に、Warm-upを10エポック行い、その時はXXXで学習する。
In-and-out Trusted Set
には入っていく一方のみならず、不適格だと思われるデータをに戻すこともある。データを加えるたびに評価し、信頼度が低いサンプルだったら取り出している。
Soft-labels
Pseudo Labelとしては、Hard Labelではなく識別器の予測結果のCalibrationのをそのまま使っている。
Self-Calibrated Loss Reweighting
先ほどのに手を加えたものとして、nnPUの部分でUnlabeledについて、nnPUの式のみならず、Soft Pseudo Labelを用いたCross Entropyも使うように拡張する。この時、以下のようにそれぞれの重みを置く。この重みをうまく制御することで、学習をよくしていきたい。
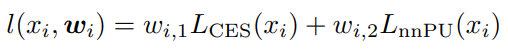
この重みについては以下の手順で学習していく。
- を使った損失関数を用いて、勾配降下法で更新する。
- 訓練に使わない、Validation Setに対してまず仮の重みを計算する。
- 重みを0に固定しての勾配を求めるのは、ある初期化された基準点だからという考え。
- はこの右辺には直接かかわっていないが、クロスエントロピーを計算するためのパラメタは1で更新している。ここで、を使っておりその時を使っているので、Validation Set学習の結果で更新している。
- 重みが0であるときの勾配が0ならば更新は止まるが、これは重み点が0において最適な値を見つけたから?でも重みは0として使ってるわけでもないし不思議な判定だ…
- このように、負のGradientにならないようにClipして最後に新しいGradientの要素の和は1となるように正規化して、これをとして使う。
ただ、このままでは使えない。(信頼できるサンプルを抜かれた後)に対してそのまま重みを学習させると、Unlabeled自体学習が不安定なのもあって重みの制限をしている。
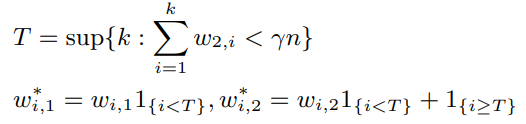
これは、重みを小さい順から並べて、和がをギリギリ超えない個数をとして
- その重みが小さい順からの個はそのままのを使う。
- それ以外のものは、クロスエントロピーの項を消して、第二項だけ使う。
これらを考えてまとめたものは以下のようなものである。の改善版みたい。
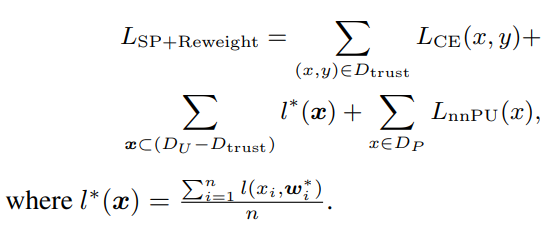
Self-supervised Consistency via Distillation
どうやら複数個のモデルを同時に学習していくらしい。
学習ペースが違うモデルの間の出力の一貫性と、モデルのパラメタを移動平均でとることで時間の前後での一貫性を保つらしい。
Consistency for Different Learning Paces: Making a Pair of Students
同じネットワークを2つ用意して、同じミニバッチで訓練をしていく。違うのは初期値と、自信があると判断する閾値だけ。なので、はそれぞれ選ぶ量が違うので違ってくる。
このように学習のペースが違ってくるが、その2つのネットワークの間でできるだけ同じペースを保って学習してほしい。これを制御するために、2つのネットワークに対してそれぞれ存在するについて、二乗誤差を計算できる。
ただし、すべてのサンプルについて計算するのではなく、nnPUのリスクが大きい(信頼度が低い)サンプルについてのみ、学習のペースをそろえてほしい。
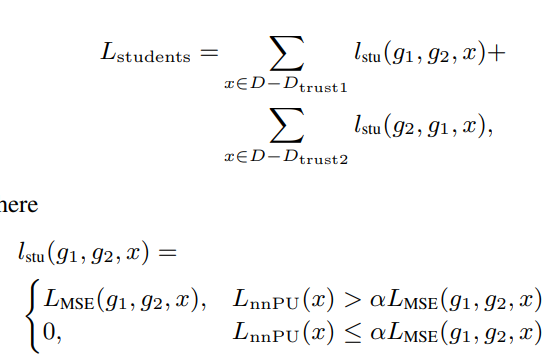
Consistency for Moving Averaged Weights: Adding Teachers to Distill
2つのに対して、パラメタである教師ネットワークを追加する。これもと同じ構造である。は以下のように更新する。つまり、学生ネットワークのパラメタを移動平均させただけ。
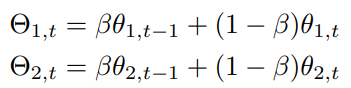
(これ教師ネットワークといってるけど別にこれの出力でラベルとかつけてない)
そして、移動平均のパラメタを使うとらの予測結果もずれないでほしいというもの。
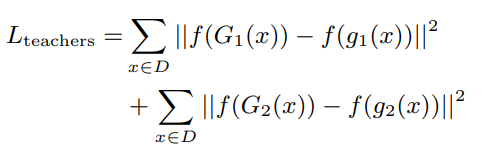
全体的には損失は以下のようになる。
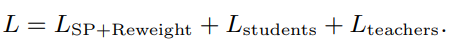
訓練の流れとしては、
- 10エポックまではWarm Up
- 10から50エポックまではSelf-paced TrainingやSelf-Calibrated Loss Reweightingをする。
- 50から250エポックは、最後に述べたDistillationだけをする。
Experiment
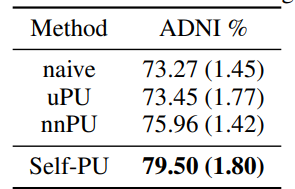
MNISTとCIFAR-10とAlzheimerで学習した。
MNISTでは奇数と偶数でPUに分けて、CIFAR-10では乗り物の0, 1, 8, 9とそれ以外を分けている。
CIFAR-10のAblation Studyはこちら。
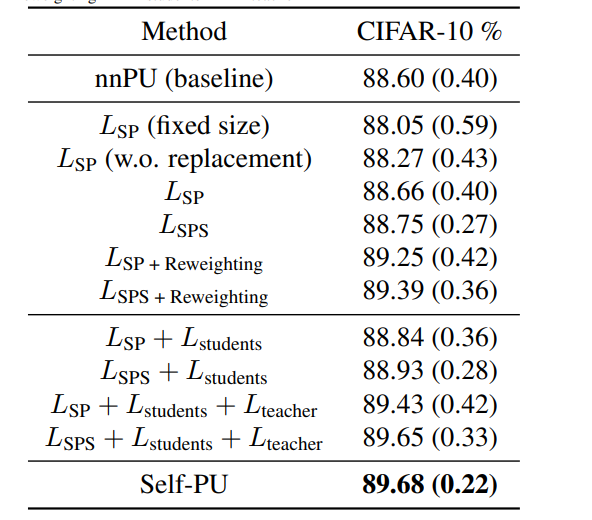
これは全体的な実験結果
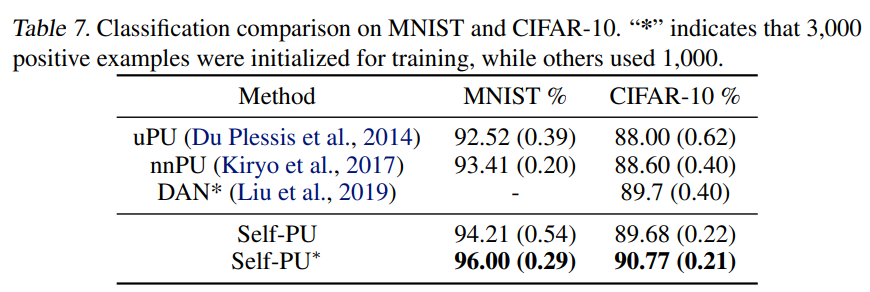
Alzheimerのデータセットは以下のようになった。